
Hadoop-MapReduce
Published:
MapReduce
Map流程
Reduce流程
shuffle流程
分布式计算需要将不同服务器上的相关数据合并到一起进行下一步计算,这就是 shuffle。 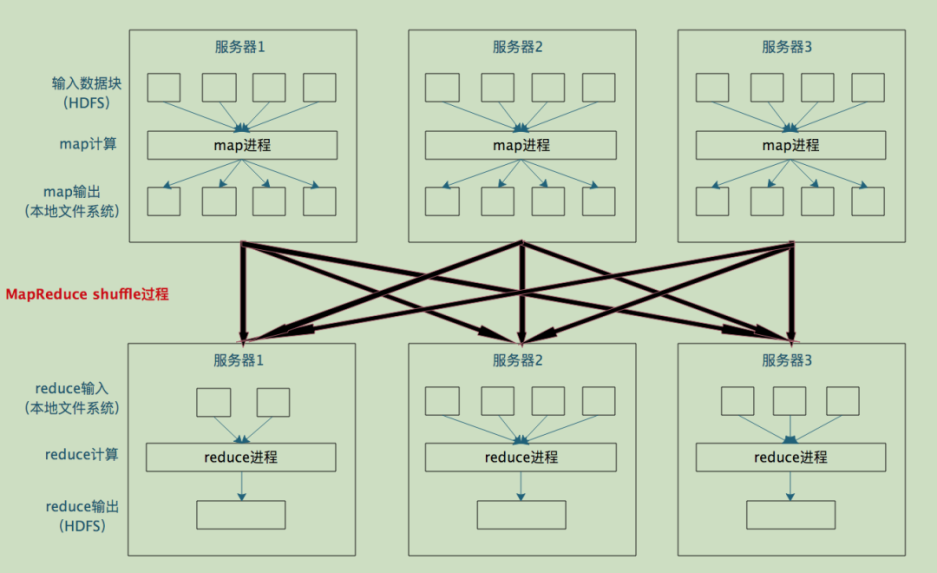 每个 Map 任务的计算结果都会写入到本地文件系统,等 Map 任务快要计算完成的时候, MapReduce计算框架会启动 shuffle 过程,在 Map 任务进程调用一个 Partitioner 接口,对 Map 产生的每个<Key,Value> 进行 Reduce 分区选择,然后通过 HTTP 通信发送给对应的 Reduce 进程。这样不管 Map 位于哪个服务器节点,相同的 Key 一定会被发送给相同的 Reduce 进程。Reduce 任务进程对收到的 <Key, Value> 进行排序和合并,相同的 Key 放在一起,组成一个 <Key, Value 集合 > 传递给 Reduce 执行。 MapReduce 框架默认的 Partitioner 用 Key 的哈希值对 Reduce 任务数量取模,相同的 Key 一定会落在相同的 Reduce 任务 ID 上。
每个 Map 任务的计算结果都会写入到本地文件系统,等 Map 任务快要计算完成的时候, MapReduce计算框架会启动 shuffle 过程,在 Map 任务进程调用一个 Partitioner 接口,对 Map 产生的每个<Key,Value> 进行 Reduce 分区选择,然后通过 HTTP 通信发送给对应的 Reduce 进程。这样不管 Map 位于哪个服务器节点,相同的 Key 一定会被发送给相同的 Reduce 进程。Reduce 任务进程对收到的 <Key, Value> 进行排序和合并,相同的 Key 放在一起,组成一个 <Key, Value 集合 > 传递给 Reduce 执行。 MapReduce 框架默认的 Partitioner 用 Key 的哈希值对 Reduce 任务数量取模,相同的 Key 一定会落在相同的 Reduce 任务 ID 上。